Token Superposition Training (TST) offers a breakthrough for LLM deployment by reducing training time by 2.5x. Learn how this two-phase method optimizes compute efficiency without modifying model architecture.
Token Superposition Training (TST) is a two-phase pre-training method developed by Nous Research that reduces wall-clock training time by up to 2.5x at matched FLOPs — without modifying model architecture, tokenizer, optimizer, or inference behavior. For teams navigating the economics of large language model (LLM) deployment, where compute costs can run into millions of dollars per training run, TST represents one of the most practically accessible efficiency gains to emerge in 2026.
This tutorial breaks down exactly how TST works mechanically, why it produces the speedup it claims, and how you can reason about applying it across model scales from 270M to 10B parameters.
What You'll Learn
By the end of this article, you'll understand:
- The core mechanics of token embedding "bags" and why they accelerate Phase 1 training
- How Phase 2 restores standard next-token prediction without architectural surgery
- Why TST scales predictably from 270M to 10B parameter models
- The practical implications for LLM deployment economics and training infrastructure
Prerequisites: Familiarity with transformer pre-training, tokenization pipelines, and basic understanding of FLOPs as a compute metric.
The Problem TST Solves
Standard LLM pre-training is brutally sequential at the token level. Each forward pass processes one token position at a time in the attention mechanism's causal chain, and the model must predict the next token at every step. This means that for a sequence of length L, you're running L prediction targets per sample — most of which, especially in early training, carry very low signal relative to their compute cost.
The core insight behind Token Superposition Training is deceptively simple: early in training, the model doesn't need full token-level resolution to learn useful representations. You can compress the input signal, train faster, and then sharpen the resolution in a second phase — recovering full next-token prediction capability without starting over.
This is the same intuition behind curriculum learning and progressive training strategies, but TST operationalizes it at the embedding level in a way that requires zero changes to the model's final inference behavior.
Mechanism 1 — Averaging Contiguous Token Embeddings into Bags
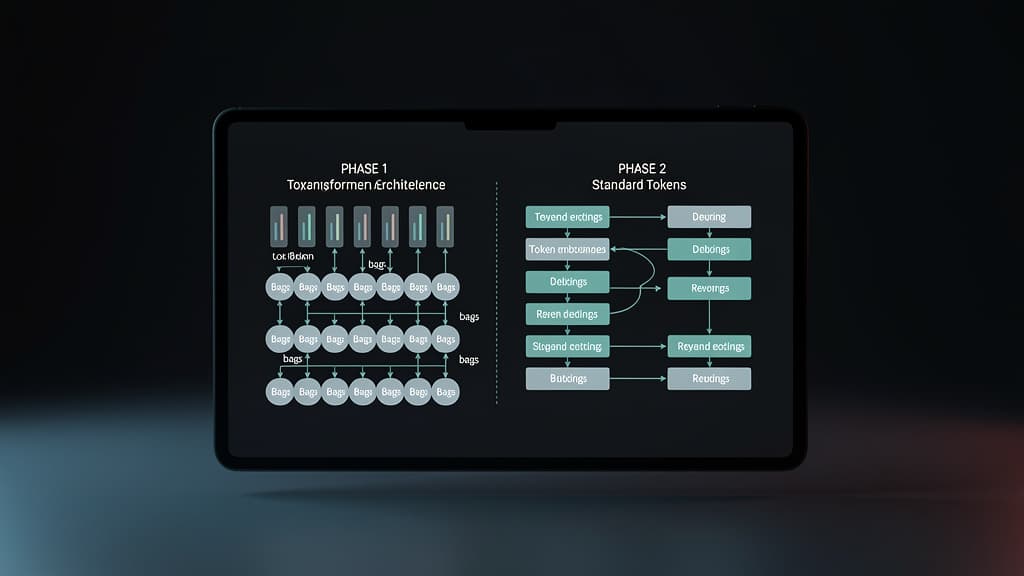
Phase 1 of TST replaces individual token embeddings with averaged "bags" of contiguous tokens. Here's the step-by-step mechanics:
Step 1: Define a Bag Size
Contiguous tokens in a sequence are grouped into fixed-size windows — think of it as a sliding bag of size k. For each bag, the token embeddings are averaged element-wise into a single vector.
Tokens: [T1, T2, T3, T4, T5, T6] Bag size k=2: Bags: [(T1+T2)/2, (T3+T4)/2, (T5+T6)/2]
This immediately reduces the effective sequence length by a factor of k, which has a quadratic effect on attention computation (since attention scales as O(L²)). Halving the sequence length cuts attention FLOPs by roughly 4x for that component.
Step 2: Feed Bags Through the Standard Transformer
Critically, the transformer architecture itself is unchanged. The same attention heads, feed-forward layers, and positional encodings operate on the compressed bag representations. No new modules, no architectural modifications. The model simply sees shorter sequences with denser semantic content per position.
Step 3: Predict at the Bag Level
During Phase 1, the training objective shifts to predicting the next bag rather than the next individual token. The loss is computed over these compressed targets, which means each gradient update covers more semantic territory per step.
Key insight: Because the model is processing fewer positions per sequence, it can iterate over more training data — measured in raw text tokens — within the same wall-clock time budget. This is the primary source of the 2.5x speedup.
Mechanism 2 — Phase Transition Without Architectural Surgery
The elegance of TST's design becomes clear at the phase boundary. After Phase 1 training on bag-averaged embeddings, transitioning to Phase 2 requires no checkpoint surgery, no new optimizer states, and no tokenizer changes.
Step 4: Revert to Standard Token Embeddings
In Phase 2, the model simply reverts to standard next-token prediction on individual token embeddings. The same embedding matrix that was initialized before Phase 1 is now used at full resolution. Because the embedding space was never fundamentally altered — only the inputs were averaged — the weights learned in Phase 1 transfer cleanly.
Step 5: Standard Next-Token Prediction Resumes
Phase 2 operates identically to conventional pre-training. The model fine-tunes its token-level predictions on top of the representations already shaped by Phase 1's compressed training signal.
Phase 1: Bag embeddings → Transformer → Bag-level loss ↓ Phase 2: Token embeddings → Same Transformer → Token-level loss
This two-phase handoff is what makes TST deployment-friendly. The final model checkpoint is indistinguishable from a standard pre-trained model at inference time. No changes to serving infrastructure, quantization pipelines, or downstream fine-tuning workflows are required.
According to Nous Research's validation, TST produces matched quality at matched FLOPs across model sizes from 270M to 10B parameters — meaning you're not trading model quality for speed, you're trading wall-clock time for the same effective compute utilization.
Mechanism 3 — Scale-Invariant Validation Across Model Sizes
One of the most practically significant aspects of TST is that it doesn't require per-scale tuning. Nous Research validated the approach across four model sizes — 270M, 600M, 3B, and 10B parameters — with consistent results.
Why Scale Invariance Matters for LLM Deployment
For teams operating at different budget tiers, a technique that only works at one scale is operationally limited. TST's scale-invariant behavior means:
- Small teams running 270M–600M parameter experiments get the same proportional speedup as hyperscalers running 10B+ runs
- Scaling laws experiments that sweep across multiple model sizes benefit uniformly
- Ablation studies conducted at smaller scales produce results that transfer to larger training runs
Step 6: Calibrate Phase Split Ratio
The primary tuning knob in TST is the ratio of Phase 1 to Phase 2 training. Nous Research's results suggest the optimal split is not a fixed universal value — it depends on the target model size and dataset composition. The general principle:
- More Phase 1 → faster early training, but diminishing returns if Phase 2 is too short to recover full token-level resolution
- More Phase 2 → closer to standard pre-training behavior, reducing the wall-clock advantage
For practitioners, the recommended starting point is to treat the phase ratio as a hyperparameter and validate on a smaller proxy model before committing to a full-scale run.
What the 2.5x Speedup Actually Means in Practice
Let's ground this in deployment economics. A training run that would take 10 days on a given compute cluster now completes in roughly 4 days under TST. At current H100 spot pricing (approximately $2.50–$3.50/GPU-hour depending on provider and region), a 100-GPU cluster run drops from ~$600K to ~$240K in wall-clock cost for the same effective FLOPs.
This isn't a FLOPs reduction — TST matches FLOPs, not reduces them. The speedup comes from higher hardware utilization per unit time: the model processes more tokens per second because sequences are shorter in Phase 1, keeping GPUs busier and reducing idle time in the data pipeline.
For organizations where large language model LLM deployment timelines are gated by training duration rather than raw compute budget, TST directly compresses the iteration cycle — enabling faster experimentation, more ablations per quarter, and earlier deployment windows.
Integration Checklist for Practitioners
Before adopting TST in your training pipeline, verify the following:
- Tokenizer compatibility: TST requires no tokenizer changes, but confirm your tokenizer produces contiguous integer token IDs that can be cleanly grouped into bags
- Embedding matrix initialization: Ensure your Phase 1 initialization strategy is consistent with your Phase 2 embedding usage
- Optimizer state continuity: Verify that your optimizer (AdamW or equivalent) carries state cleanly across the phase boundary without requiring a reset
- Evaluation cadence: Schedule eval checkpoints in both phases to catch any Phase 1 → Phase 2 quality discontinuities early
- Bag size ablation: Run a small proxy experiment (270M scale) to identify the optimal bag size k for your dataset before scaling up
Limitations and Open Questions
TST is not a universal solution. A few constraints worth noting:
Bag size sensitivity: Larger bags compress more aggressively and increase Phase 1 speed but may degrade the quality of representations transferred to Phase 2. The optimal k is dataset- and domain-dependent.
Phase 2 length requirements: If Phase 2 is too short relative to Phase 1, the model may not fully recover token-level prediction sharpness before the training budget is exhausted.
Instruction tuning and RLHF compatibility: Nous Research's validation covers pre-training. Whether TST-trained base models respond identically to standard post-training pipelines (SFT, DPO, RLHF) at matched quality is an open empirical question worth validating per use case.
Sequence length distribution: Datasets with highly variable sequence lengths may require adaptive bagging strategies rather than fixed-size windows.
The Bigger Picture for LLM Deployment Economics
TST arrives at a moment when the compute economics of LLM development are under intense scrutiny. As foundation model training costs have escalated — with frontier runs reportedly exceeding $100M — even incremental efficiency gains at the pre-training stage have outsized downstream value.
What makes TST particularly noteworthy is its zero-infrastructure-change deployment profile. Unlike approaches that require custom attention kernels, modified tokenizers, or specialized serving hardware, TST's output is a standard model checkpoint. The efficiency gain is captured entirely during training, and the resulting model slots into any existing LLM deployment workflow without modification.
For the broader ecosystem of teams building on open-weight models or training their own domain-specific LLMs, this is the kind of practical efficiency unlock that compounds: faster training cycles mean more iterations, more iterations mean better models, and better models mean more competitive LLM deployment outcomes.
Source: Nous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter Models — MarkTechPost, May 13, 2026
Last reviewed: May 14, 2026


