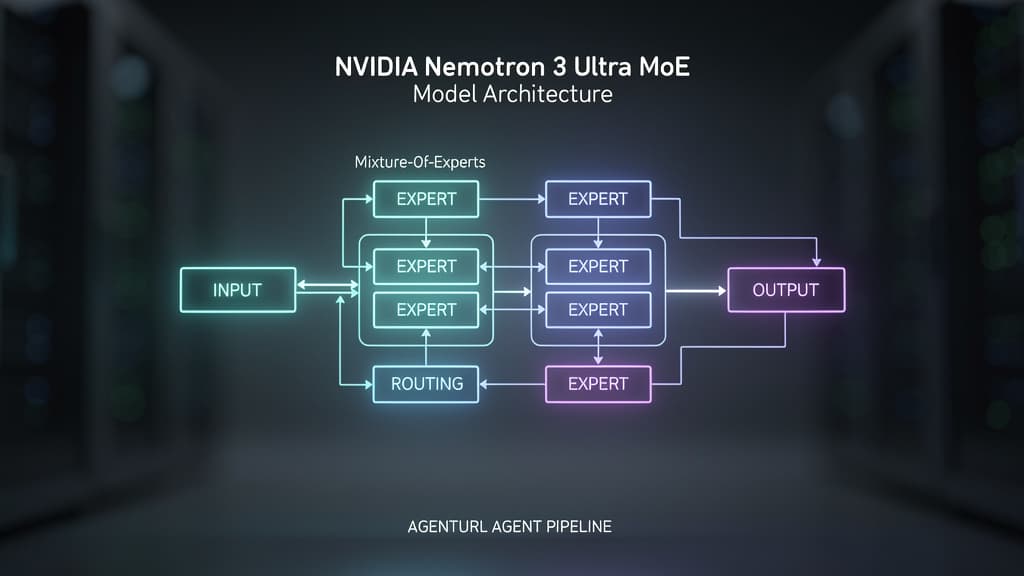
NVIDIA's Nemotron 3 Ultra introduces a 1M-token context window and MoE architecture that fundamentally changes how you should design and scale autonomous agent systems in production.
What You'll Achieve — and What You Need to Know First
If your team is deploying autonomous agents in enterprise environments, AI agent deployment best practices are no longer optional — they're the difference between a system that runs for minutes and one that runs for hours. NVIDIA's newly released Nemotron 3 Ultra changes the calculus significantly.
Nemotron 3 Ultra is a 550B total parameter (55B active) open Mixture-of-Experts hybrid Mamba-Transformer model designed explicitly for long-running agents. It ships with a 1M-token context window, up to 6x higher inference throughput than comparable open LLMs, and is released under the OpenMDW-1.1 license with open weights, training data, and training recipes.
This tutorial breaks down three architectural reasons Nemotron 3 Ultra changes how you should design, deploy, and scale agent systems — and gives you a practical framework for each. You don't need to retrain the model to benefit. You need to understand what its architecture enables and restructure your deployment patterns accordingly.
Prerequisites: Familiarity with LLM inference pipelines, basic understanding of agent orchestration frameworks (LangGraph, AutoGen, or similar), and access to multi-GPU infrastructure (NVIDIA H100 or equivalent recommended for full-scale deployment).
Reason 1: The 1M-Token Context Window Eliminates Retrieval Bottlenecks in Long-Running Agents
Why Context Length Is the Real Agent Constraint
Most agent deployment failures aren't model quality failures — they're context management failures. An agent working through a multi-step enterprise task (auditing a codebase, synthesizing research across dozens of documents, managing a multi-turn negotiation workflow) constantly runs into the same wall: the model forgets what it did three steps ago.
The standard workaround is Retrieval-Augmented Generation (RAG) — chunk your documents, embed them, retrieve the relevant pieces per step. RAG works, but it introduces latency at every retrieval call, creates retrieval errors when the relevant context is ambiguous, and breaks down for tasks where sequential reasoning across the full history is essential.
Nemotron 3 Ultra's 1M-token context window changes the architectural choice entirely.
A 1M-token context window can hold approximately 750,000 words — enough to ingest the full text of a 2,500-page technical document, an entire codebase, or hundreds of prior agent turns without truncation.
How to Restructure Your Agent Memory Architecture
Step 1: Audit your current context budget. Map every agent in your pipeline and identify where you're currently truncating, summarizing, or offloading to retrieval. These are your highest-value targets for architectural simplification.
Step 2: Shift from retrieval-first to context-first for high-stakes workflows. For tasks where retrieval errors carry real cost (legal document review, financial analysis, security audits), load the full source material into context rather than relying on chunk retrieval. With a 1M-token window, this is now feasible for most enterprise document sets.
Step 3: Preserve full agent turn history. Instead of summarizing prior turns to save tokens, retain the complete interaction log in context. This gives the model access to its own reasoning chain, reducing hallucination loops where the agent contradicts its earlier conclusions.
Step 4: Reserve retrieval for truly external, dynamic data. RAG remains valuable for real-time data (live APIs, databases that change during a session). Use it selectively rather than as a universal workaround for context limits.
python
Example: Loading full document corpus into agent context
instead of chunking for retrieval
def build_agent_context(documents: list[str], task_prompt: str) -> str: full_corpus = "\n\n---\n\n".join(documents) system_context = f"""You are an enterprise analysis agent.
FULL DOCUMENT CORPUS:
{full_corpus}
TASK:
{task_prompt}
Reason across the entire corpus. Do not request additional context."""
return system_context
With Nemotron 3 Ultra's 1M-token window, full_corpus
can be hundreds of documents without truncation
Reason 2: The MoE Architecture Delivers 6x Throughput — Restructure Your Parallelism Model
Understanding Why 55B Active Parameters Matter More Than 550B Total
The headline number — 550B parameters — sounds computationally prohibitive. The operative number is 55B active parameters per forward pass. This is the signature of a well-designed Mixture-of-Experts architecture: the model routes each token through a subset of specialized expert layers rather than activating the full parameter set.
The result, according to NVIDIA's release, is up to 6x higher inference throughput compared to comparable open LLMs. For agent deployments, this isn't just a cost metric — it's an architectural unlock.
6x higher inference throughput means an agent that previously required 6 GPU-hours of wall-clock time for a complex task can now complete the equivalent workload in approximately 1 GPU-hour, enabling sustained autonomous operation at enterprise scale.
How to Restructure Your Agent Parallelism
Step 1: Move from sequential to parallel agent execution. If your current pipeline runs agents in a chain (Agent A finishes → Agent B starts), the throughput headroom from MoE enables genuine parallelism. Spawn multiple specialized sub-agents simultaneously and merge their outputs.
Step 2: Right-size your infrastructure allocation. Because active parameter count (55B) drives memory bandwidth requirements — not total parameter count — you can serve Nemotron 3 Ultra on fewer GPUs than a dense 550B model would require. Benchmark your specific workload, but expect meaningful GPU memory efficiency gains versus naive parameter-count estimates.
Step 3: Use throughput headroom for agent self-verification. One underutilized best practice: allocate a portion of your inference budget to a second agent pass that critiques the first agent's output. With 6x throughput improvement, this verification step becomes economically viable in production pipelines that previously couldn't afford it.
yaml
Example agent orchestration config leveraging parallel execution
(LangGraph-style pseudoconfig)
agent_graph: parallel_branches: - agent: research_agent model: nemotron-3-ultra context_budget: 400000 # tokens task: "Synthesize market research corpus"
- agent: risk_agent
model: nemotron-3-ultra
context_budget: 300000
task: "Identify regulatory risks in same corpus"
- agent: competitor_agent
model: nemotron-3-ultra
context_budget: 300000
task: "Extract competitive positioning signals"
merge_node: agent: synthesis_agent inputs: [research_agent, risk_agent, competitor_agent] task: "Produce unified strategic brief"
Step 4: Plan for burst workloads. Enterprise agent deployments often have uneven load profiles — a legal team might trigger 50 simultaneous document review agents at end of quarter. The throughput efficiency of MoE architecture makes burst provisioning significantly cheaper. Build autoscaling policies around active parameter memory footprint, not total parameter count.
Reason 3: The Hybrid Mamba-Transformer Design Enables Sustained Operation — Rethink Your Session Management
What the Mamba-Transformer Hybrid Actually Solves
This is the most technically significant architectural choice in Nemotron 3 Ultra, and the least discussed in surface-level coverage.
Standard Transformer architectures have a well-known problem for long-running agents: KV-cache memory grows linearly with sequence length. At 1M tokens, a pure Transformer's KV-cache would be enormous — making sustained long-context operation practically expensive even if technically possible.
Mamba is a state space model (SSM) architecture that processes sequences with fixed-size recurrent state rather than growing KV-cache. The hybrid Mamba-Transformer design in Nemotron 3 Ultra combines Transformer attention layers (for tasks that benefit from full attention over recent context) with Mamba layers (for efficient long-range sequence processing with bounded memory cost).
The practical consequence: Nemotron 3 Ultra can sustain operation across very long contexts without the memory blowout that would otherwise make 1M-token inference impractical.
How to Restructure Your Session Management
Step 1: Extend your agent session lifetimes. If your current architecture terminates and restarts agent sessions to manage memory, you can now extend session duration significantly. Design your session management layer to keep agents alive across what were previously natural breakpoints.
Step 2: Instrument for genuine long-session monitoring. Longer sessions require better observability. Implement per-turn logging of agent reasoning quality, not just task completion. Agents that drift in long sessions need to be caught before they compound errors across hundreds of steps.
python
Session monitoring pattern for long-running agents
class AgentSessionMonitor: def init(self, drift_threshold: float = 0.15): self.turn_log = [] self.drift_threshold = drift_threshold
def log_turn(self, turn_id: int, output: str,
confidence_score: float, task_alignment_score: float):
self.turn_log.append({
"turn": turn_id,
"output_length": len(output),
"confidence": confidence_score,
"alignment": task_alignment_score
})
# Flag potential drift after turn 20
if turn_id > 20:
recent_alignment = sum(
t["alignment"] for t in self.turn_log[-5:]
) / 5
if recent_alignment < (1 - self.drift_threshold):
self.trigger_realignment_checkpoint(turn_id)
def trigger_realignment_checkpoint(self, turn_id: int):
# Inject original task specification back into context
# and prompt agent to restate its current objective
print(f"[MONITOR] Alignment drift detected at turn {turn_id}. "
f"Triggering realignment checkpoint.")
Step 3: Use the open training recipes to fine-tune for your domain. The OpenMDW-1.1 release includes not just weights but training data and recipes. For enterprise teams with proprietary workflows, this is a significant unlock — you can fine-tune Nemotron 3 Ultra on your internal processes and agent interaction patterns without starting from scratch.
Step 4: Benchmark KV-cache behavior at your target context lengths. Even with the Mamba-Transformer hybrid's memory efficiency advantages, your specific hardware configuration will determine practical limits. Run systematic benchmarks at 128K, 256K, 512K, and 1M token lengths before committing to a production architecture that assumes full 1M-token utilization.
Putting It Together: A Deployment Checklist
Before you ship a Nemotron 3 Ultra-based agent system into production, run through these checkpoints:
Context Architecture
- Audited which workflows genuinely benefit from long-context vs. retrieval
- Full document loading tested at target corpus sizes
- Retrieval reserved for dynamic/external data only
Parallelism and Throughput
- Sequential agent chains refactored to parallel where task dependencies allow
- Infrastructure sized to 55B active parameter footprint, not 550B total
- Self-verification pass budgeted into inference cost model
Session Management
- Session lifetime extended and tested under realistic long-task conditions
- Per-turn monitoring and drift detection instrumented
- Fine-tuning plan scoped if domain-specific adaptation is needed
Licensing and Compliance
- OpenMDW-1.1 license terms reviewed with legal team for your use case
- Training data provenance documented for compliance requirements
What This Architecture Signals for Enterprise Agent Deployment
Nemotron 3 Ultra isn't just a larger model — it's a purpose-built architecture for a specific deployment pattern that enterprises have been struggling to achieve: agents that operate autonomously over long time horizons, across large information sets, without constant human re-injection of context.
The combination of 1M-token context, MoE throughput efficiency, and Mamba-Transformer memory management addresses three distinct failure modes that have kept enterprise agent deployments shallow. The open weights and training recipes under OpenMDW-1.1 mean teams don't have to wait for API access or accept a black-box deployment.
The best practices described here — context-first architecture, parallel agent execution, extended session management — aren't specific to Nemotron 3 Ultra. They're the patterns this architecture finally makes viable at production scale.
Sources:
- NVIDIA Nemotron 3 Ultra release coverage: https://www.marktechpost.com/2026/06/04/nvidia-ai-releases-nemotron-3-ultra-an-open-550b-mixture-of-experts-hybrid-mamba-transformer-for-long-running-agents/
- Mamba architecture paper: Gu & Dao, "Mamba: Linear-Time Sequence Modeling with Selective State Spaces" (2023)
- Mixture-of-Experts scaling research: Fedus et al., "Switch Transformers" (2022)
Last reviewed: June 05, 2026